Google Gemini 3.5 Pro Launch: What’s New and How It Compares
Google Gemini 3.5 Pro Launch: What’s New and How It Compares
A model I cannot download yet is sitting on my to-do list, and I almost rearranged my whole workflow around it. That is the trap I want to spare you. This post is a plain decision memo on the Google Gemini 3.5 Pro launch: what’s new and how it compares to the tools you already pay for, what Google actually confirmed, and what is still a guess dressed up as a spec sheet.
Here’s my one-line position up front. As of June 20, 2026, the model is not something you can use. It was announced, not shipped. So the honest job today is not a review. It is a decision: should you wait, switch, or ignore the noise?
I’ll walk through the timeline, the confirmed-versus-rumored split, a tier-by-tier look at who gets it first, and the framework I use so a version number never hijacks my Tuesday again.
Where the Gemini 3.5 Pro launch actually stands
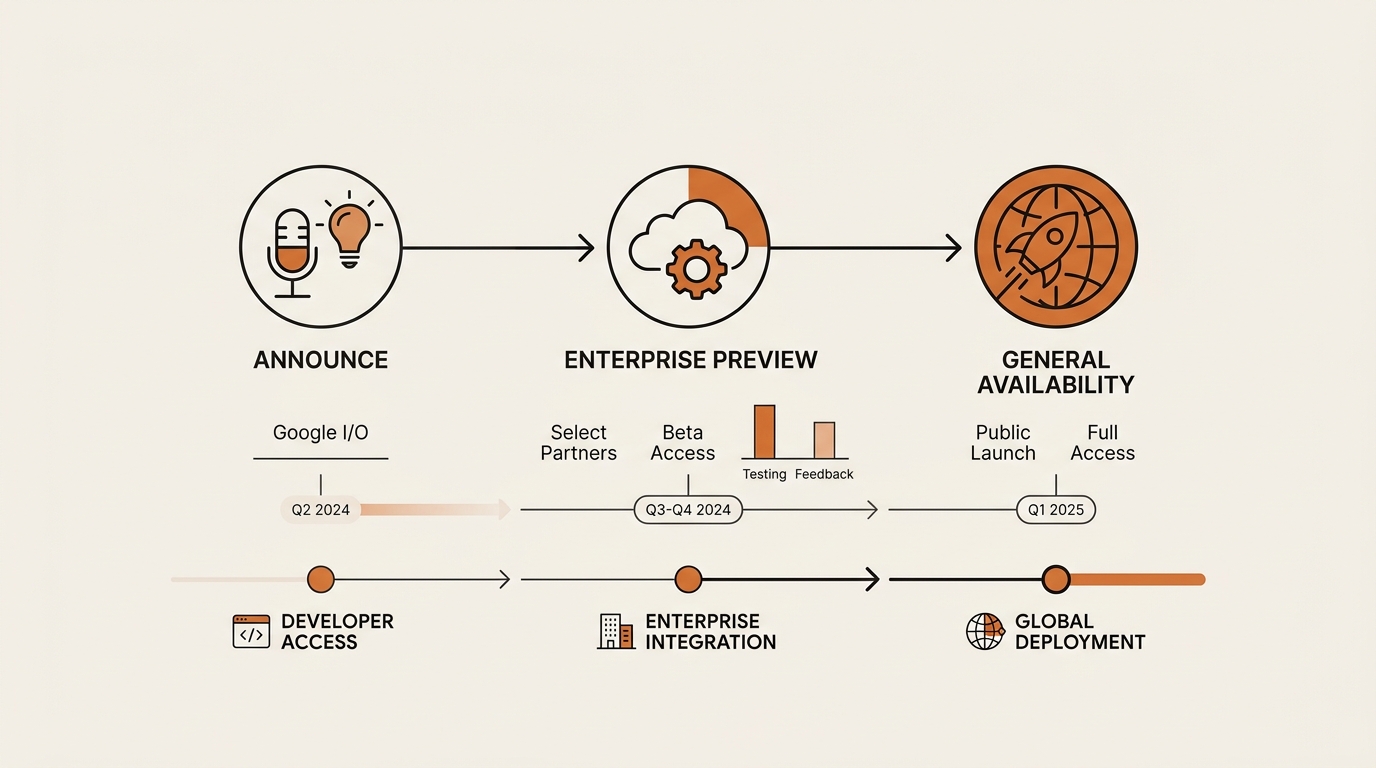
Let me state the boring truth before the hype. At Google I/O on May 19, 2026, Google announced Gemini 3.5 Pro and shipped its smaller sibling, Gemini 3.5 Flash. Sundar Pichai’s framing was basically “give us until next month.” That puts the public release window in June, and you can read the official I/O 2026 announcements for the primary source.
As of June 19, 2026, Pro was still in limited preview for select Vertex AI enterprise customers. Not the consumer app. Not AI Studio. Not a public subscription. If you read a blog claiming it tested Pro and ranked it against GPT-5.5, treat that with care, because the model is not open for that yet.
Confirmed vs. rumored, in 50 words: Confirmed: Pro was announced at I/O, targets a June launch, and is still in enterprise preview; Flash already shipped. Rumored: Pro’s final price and every benchmark score floating around. When you see a Pro number, ask whether Google said it or someone guessed it.
That distinction matters more than any spec. Most of the search results for this topic recite “2M tokens, Deep Think, June, maybe 10x pricing” and present all four as equal facts. Only two of those are confirmed. I would rather lose a flashy table than mislabel a rumor as a result.
What Google confirmed about Gemini 3.5 Pro
Here is what stands on the record, separated cleanly from the guesswork.
Gemini 3.5 Flash is real and you can use it today. It went GA on May 19, 2026, with a 1M-token context window, priced at $1.50 per million input tokens and $9 per million output. It is free in the Gemini app and in AI Mode in Search. Google reported it beats the older Gemini 3.1 Pro on coding and agentic tasks while running roughly four times faster. Read that price carefully: $1.50 and $9 belong to Flash, not Pro. The internet keeps borrowing that figure for Pro. It is wrong to do so.
For Pro itself, Google has confirmed two headline targets. First, a 2M-token context window, double Flash’s window and the largest production context announced so far, roughly 1.5 million words. Second, a Deep Think reasoning mode that spends extra compute working through multi-step problems before it answers. Both are stated targets for a model that has not shipped, so I treat them as Google’s promise, not a measured result.
| Item | Status | What Google actually said |
|---|---|---|
| Announced at I/O | Confirmed | May 19, 2026 |
| Public launch (GA) | Targeted | June 2026, still preview as of June 19 |
| 2M-token context | Targeted | Double Flash’s 1M window |
| Deep Think reasoning | Targeted | Multi-step reasoning mode |
| Final Pro pricing | Rumored | No official number; estimates conflict |
| Pro benchmark scores | Rumored | None measured; all extrapolated from Flash |
That table is the whole point of this post. Notice there are no benchmark numbers in it, because there are none to honestly print yet.
What is rumored, and why I won’t repeat it as fact
Pricing is where the topic gets messy. One source estimates around $15 per million input and $60 per million output, a roughly 10x jump over Flash. Other estimates land near $2 and $12, which would undercut the high tiers of its rivals. These are guesses, and they disagree by a factor of seven. Google has not published a Pro price. So I will not pick one and call it the answer.
Benchmarks are the same story. Every Pro score circulating is an extrapolation from the Flash-versus-3.1-Pro gap, not a measurement. The only fair claim I can make is this: Flash already beats last year’s Pro on coding, so the new Pro is expected to be strong. Expected is not the same as proven.
If you want neutral background on how the Gemini 3 line evolved into this point, the Wikipedia entry on Gemini 3) tracks the version history without the marketing gloss. For the spec baseline of the immediate predecessor, the official Gemini 3.1 Pro model card is the primary record.
How it compares to GPT-5.5 and Claude right now
You probably already pay for one frontier model, so “how it compares” is the real query. The honest answer in June 2026 is that there is nothing to compare on yet, and I want to be straight about that.
OpenAI’s frontier is GPT-5.5, launched April 23, 2026. Anthropic’s frontier is its newest Claude line, Fable 5, announced June 9, 2026, sitting above Claude Opus 4.8. Both are shipped, public, and benchmarked. Gemini 3.5 Pro is not. There are no head-to-head Pro benchmarks because the model is not out. Any table you see ranking Pro against those two is filling cells with hope.
The one confirmed differentiator worth your attention is context length. A targeted 2M-token window is bigger than the roughly 1M you get from Gemini Flash, and bigger than the windows most Claude and GPT tiers expose to a normal subscriber. If your work involves feeding huge documents in one pass, that is the spec to watch. For background on how rival labs frame their own context and pricing, Anthropic’s model documentation is a useful, current reference.
The lab rivalry behind these launches is its own topic. I unpacked the money and momentum side of it in my read on the Anthropic and OpenAI IPO outlook, which sets the context for why Google keeps shipping fast.
Which tier reaches you first
Here is the part the spec sheets skip. A frontier model launch is not one event. It is a slow trickle down a ladder, and a non-developer sits near the bottom rung. Knowing that ladder is what keeps me calm during launch week.
Frontier specs land in enterprise and API tiers first. Pro proves that perfectly: it is in Vertex AI enterprise preview before it is anywhere a normal person can reach. The capability that excites the headlines is, for now, a procurement line item, not a button in your app.
| Tier | Who it serves | When the new model lands |
|---|---|---|
| Enterprise preview (Vertex AI) | Large companies, dev teams | First — Pro is here now |
| Public API | Developers, builders | Next, at full token prices |
| Paid consumer app | ChatGPT Plus / Claude Pro / Gemini subscribers | Later, often capped |
| Free app tier | Everyone else | Last, usually a smaller model |
Read that ladder against your own life. If you pay $20 a month for a consumer app, the frontier model usually reaches you weeks or months after the announcement, often rate-limited. The free tier almost never gets the top model at all. So “Pro launched” rarely means “Pro is in your hands this week.”
This is the same reason I keep telling people you don’t have to chase every release. I wrote a whole framework on how to keep up with AI without burning out, and this launch is a textbook case of it.
Where I was wrong about chasing version numbers
I’ll own the mistake that taught me this. When GPT-5.5 launched in April, I spent an evening rewiring my note-summarizing prompt to use it, convinced the jump from the prior model would sharpen my output. I moved my templates, re-tested my standard tasks, the works.
The result? My weekly summaries read the same. My draft emails read the same. The bottleneck in my actual work was never the model’s raw IQ. It was that I had not defined what a good summary looked like for me. I had upgraded the engine on a car with no destination set.
That evening cost me about two hours and zero improvement. The lesson stuck harder than any benchmark. A version bump changes the ceiling of what is possible. It rarely changes the floor of what you personally do on a Tuesday. My note workflow needed a clearer goal, not a smarter model.
So when the launch buzz started, I felt the old itch and recognized it. The honest question was not “is Pro better than what I have.” It was “does anything in my current work actually fail because of the model I use.” When I checked, the answer was no.
The framework I use to decide on any model launch
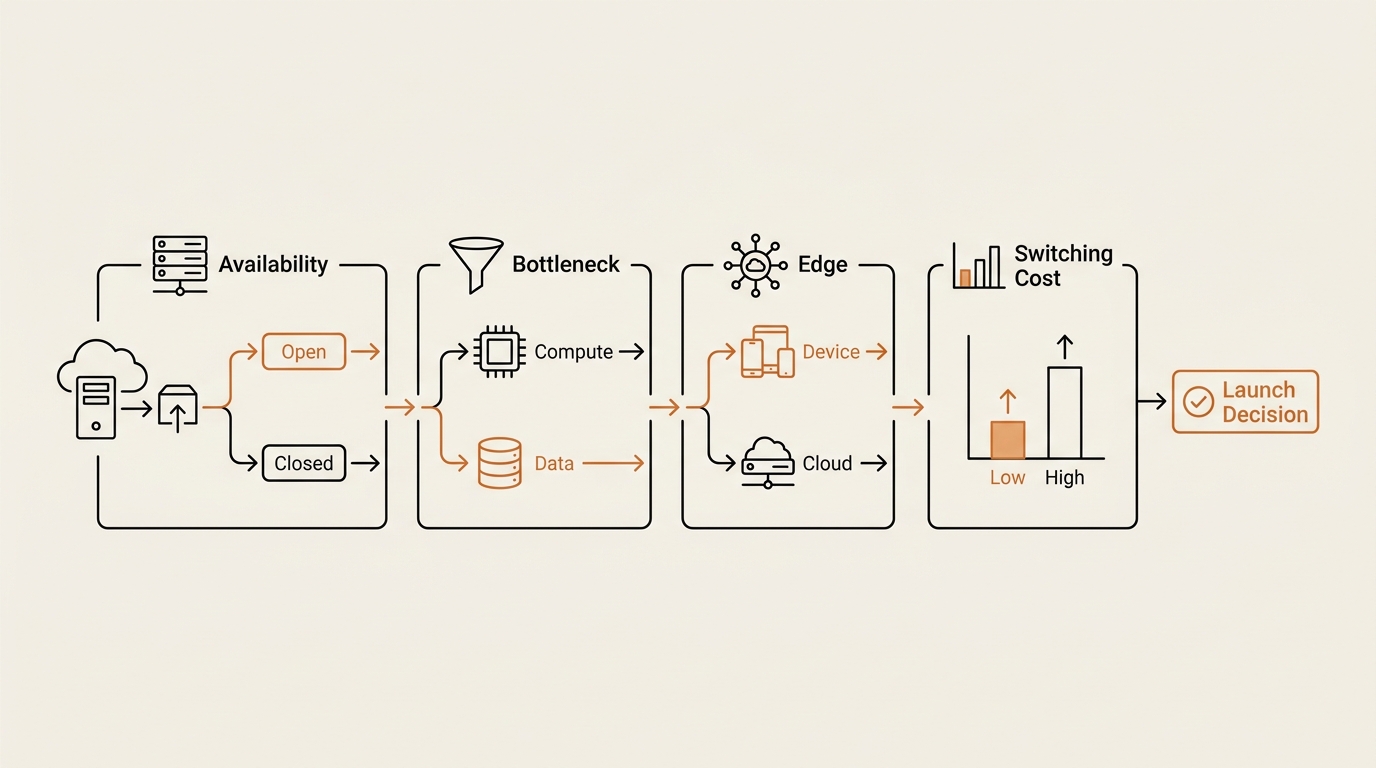
This is the memo part. When a frontier model drops, I run four quick checks before I touch my stack. They take five minutes and they have saved me dozens of wasted evenings.
First, availability. Can I even access it on the tier I pay for? If it is enterprise-only, like Pro is today, the decision is automatic: I wait. There is nothing to evaluate.
Second, the named bottleneck. What specific task in my week currently fails or annoys me? If I cannot name one, no model fixes it. A faster engine does not fix a missing destination.
Third, the confirmed edge. Of the new model’s specs, which are confirmed, and does any confirmed one map to my named bottleneck? For Pro, the only confirmed edge is the 2M context window. If I were drowning in 500-page documents, that maps. For my email and summaries, it does not.
Fourth, the switching cost. What breaks if I move? Prompts tuned to one model do not always transfer. My time re-testing is not free. If the upside is “maybe better, unproven” and the cost is “two evenings,” I stay put.
Run those four and this launch sorts itself out fast. Not available to me, no named bottleneck it solves, one confirmed edge I don’t need, real switching cost. Verdict: wait and watch. For the agentic and Deep Think side, which ties into automating real tasks, my notes on how to use AI agents at work cover where reasoning modes earn their keep.
The one condition that would flip my answer
I am not anti-Gemini. My “wait” is conditional, and I want to name the condition so this memo is honest in both directions.
I would move if Pro ships to a tier I can reach, publishes real benchmarks, and one confirmed strength maps to a bottleneck I can actually name. Right now that is the 2M context window. The day I have a recurring task that needs me to load a giant corpus in one pass, and Pro is the cleanest way to do it at a price I can read on Google’s own page, I will switch that one workflow over. Not my whole stack. One workflow.
That is the whole difference. I do not adopt a model. I adopt it for a job. The launch is Google’s event. The decision is mine, and it is small.
FAQ
Is Gemini 3.5 Pro out yet? As of June 20, 2026, no. It was announced at Google I/O on May 19 with a June launch target, but it remains in limited Vertex AI enterprise preview. The consumer app and AI Studio do not have it yet. Gemini 3.5 Flash is the version that has actually shipped to the public.
What’s the difference between Gemini 3.5 Flash and Gemini 3.5 Pro? Flash shipped in May with a 1M-token context, priced at $1.50 input and $9 output per million tokens, free in the app. Pro targets a larger 2M-token context plus the Deep Think reasoning mode. Pro is the heavier, slower, more capable tier, but it has not launched publicly yet.
How big is the Gemini 3.5 Pro context window? Google targets 2 million tokens, double Flash’s 1 million. That is roughly 1.5 million words and the largest production context window announced so far. Treat it as a stated target, since the model is not shipped, not as a verified production figure.
How much will Gemini 3.5 Pro cost? Google has not published a price. Estimates conflict sharply, from around $2 and $12 per million tokens to around $15 and $60. None of those are official. The $1.50 and $9 figure you may see is Flash’s price, not Pro’s, so do not plan a budget on rumored Pro numbers.
Is Gemini 3.5 Pro better than GPT-5.5 or Claude? Unproven. There are no head-to-head Pro benchmarks because Pro has not shipped. Its predecessor Flash already beats last year’s Pro on coding, so expectations are high, but expectation is not measurement. Any ranking table you see today is built on guesses, not tested results.
What is Deep Think reasoning in Gemini 3.5? Deep Think is a mode that spends extra compute reasoning through a problem across multiple steps before giving an answer. It targets complex, multi-part tasks where a fast single-pass answer tends to miss. It is a confirmed feature of the line, though Pro’s specific version is not yet publicly testable.
Do I need Gemini 3.5 Pro if I already pay for ChatGPT Plus or Claude Pro? Probably not right now. For most non-developer work, like summarizing, drafting, and triage, the model you already pay for is rarely the bottleneck. Wait until Pro reaches your tier with real benchmarks, then check whether one confirmed strength solves a task you can actually name.
Don’t chase the version, chase the job
Strip the launch hype away and one thing is left standing: a version number is not a workflow. Frontier specs hit enterprise and API tiers first, then trickle down capped, and most of a non-developer’s daily wins never depended on the absolute top model in the first place.
So the Gemini 3.5 Pro launch is worth tracking, not worth restructuring around. Watch the price page. Watch which tier gets it. Name your bottleneck first, and let the model audition for that one job. Everything else is noise wearing a spec sheet.
Next in this Framework Deep Dive series, I’ll take that 2M-token context window seriously and test the real question behind it: does a giant context window actually beat a clean retrieval setup for a non-developer’s documents, or is it just a number that looks good in a keynote?
Last updated: June 20, 2026. The launch framing reflects status as of this date; if Pro ships publicly, re-verify every figure against Google’s official pages.
About the author
seonjae — Korean office worker documenting his transition into AI systems, agents, and vibe coding — without a CS background. Shipping in public.